Flash-Attention
An exact algorithm for efficient computation of self-attention.
Now that FlashAttention-2 has been out for a few months and Flash-Decoding is a thing, let’s look at the original FlashAttention algorithm and understand the thing that helps us build things we don’t really understand, but like, a lot faster how it efficiently computes self-attention.
Background
Let’s review the background material real quick.
Self-Attention
Given matrices where is the sequence length and is the embedding dimension, self-attention calculates the output as
where the is applied row-wise.
And there we go. That’s really all the deep learning background we need to make sense of this.But if you want to review self-attention or transformers, check out this post.
Let’s assign variables to the intermediate steps so we can refer back to them later in the post – and making our output .
In words, we are performing three operations – a matrix multiplication, followed by a row-wise softmax, followed by another matrix multiplication. In codeUsing einsum here because it is awesome. If you are unfamiliar, this should help. If you are familiar but not quite comfortable with it yet, I highly recommend working through the code-snippets in this excellent paper that introduced Multi-Query-Attention. , it looks like so –
import torch
# Initialize Q, K, V
N, d = 256, 16
Q, K, V = torch.randn(3, N, d).unbind(0)
# Self-Attention
S = torch.einsum('nd,md->nm', Q, K) / torch.sqrt(torch.tensor(d)) # Scores
P = torch.softmax(S, dim=1) # Probabilities
O = torch.einsum('nn,nd->nd', P, V) # Output
Calculating this way involves –
- FLOPs – the and matrix multiplications are operations each, and the softmax takes operations.
- memory in addition to the inputs/output – this is because the intermediate matrices take up storage.
This dependence limits the maximum sequence length we can put through our model. We will soon see that FlashAttention will reduce this memory burden to AND be much faster despite continuing to perform operationsThere really isn’t a way around performing operations for “exact” attention. There are other techniques, however, that approximate attention and reduce the number of operations at some expense to model quality. See Performer and Linear Attention for two such examples. by reducing the number of slow accesses to the GPU main memory. But, first, a little detour.
(Online) Softmax
Given an input vector , softmax calculates the output as
Let’s work through a small problem. Given input vectors , calculate where . That’s easy enough – first calculate using Equation and then calculate the dot product . Now let’s add a small constraint – what if we were given the elements of one at a time? Since we are seeing these elements one-by-one, we can keep a running sum to calculate the softmax denominator as we loop over our vectors and appropriately scale the previous “estimates” of . Concretely, we can run the following routine for iterations –
where and .
The is the running sum of the softmax denominator, and in each iteration, we use the previous running sum to scale our previous answer and add in the new element we just saw in the form of . At the end of iterations, our “estimate” is the actual we wanted to calculate.
Note that we got the output without ever fully materializing the softmax-ed vector and by only accessing one element at a time. You might have noticed the resemblance of our toy problem with Equation . To make it more apparent, we could replace with and observe that our update scheme doesn’t change much at all – we just have to apply the update to entries of the row at a time. This “online” softmax calculation is the bit that lets FlashAttention bring the memory usage down to from because we will never materialize all of or in memory and instead work only with “blocks” of those matrices. But more on that later.
In practice, instead of Equation , softmax is calculated like this –
This is because we don’t want softmax to overflow.
GPU Stuff
Kind of obvious when it’s spelled out but something I learnt way later than I am willing to admit is –
time-taken-to-do-a-thing-on-a-computer = time-spent-on-data-movement + time-spent-on-actual-compute
Time spent on data movement includes things like moving your input data from the main memory to the compute unit, saving/loading any intermediate results, and writing your final output back to the main memory.
The data flow in a GPU i.e. the memory hierarchy looks somethingSee this for a little more background on GPU architecture and this for the L2 Cache. like this–
HBM (High Bandwidth Memory) refers to the big but slow memory in your GPU. When you use an A100 NVIDIA GPU with a 40 GB memory, that 40GB is the HBM. SRAM is the much faster but much smaller “on-chip” memory, and there is one of these for every Streaming Multiprocessor (SM). SMs are the compute engines of the GPU with the A100 housing 108 SMs. The A100 HBM has a capacity of 40GB with a memory bandwidth of 1.5TB/s whereas the SRAM has a total capacity of 20MB (192 KB per SM) with a bandwidth of 19TB/s.
All of this is to say – we should try coding things in a way that lets us reduce any unnecessary reads/writes from/to the HBM and reuse the data in SRAM whenever we can.
Flash-Attention
Alright. So. Finally.
Flash Attention calculates Equation in memory, down from the memory requirement of the standard implementation. And while there is no getting around performing computations for exact attention, it is still up to 3x faster thanks to the reduced number of slow HBM accesses.
Here is the core idea – see how that output is but the intermediate scores () and attention matrices () are ? Well, we could use the online softmax update above to calculate the output without ever fully materializing the attention matrix in the HBM. We will load the input matrices in chunks to the SRAM, calculate only the required blocks of the score matrix and manipulate them with the online softmax update (still in SRAM) until a final chunk of the output is ready to be written out to the HBM.
Let’s make a couple of simplifications before we look at the python-esque pseudo code for the forward pass – we will assume similar row and column block sizes, and also ignore the softmax overflow correction for now.While it is absolutely necessary to do the correction in practice, it does make the pseudocode a tad bit annoying thanks to the additional bookkeeping needed for the max value correction. I have shoved the version with the overflow correction in the appendix for the more tranquil-minded.
Let be the block size and be the number of blocks. For , we will use to denote the -th block, for example, would be the matrix with contiguous rows … . flash_attn is the function that is responsible for calculating the output given input matrices , , and block-size . It breaks down the problem by partitioning into blocks of s such that the output corresponding to a is calculated by flash_attn_inner.
Here we goThe order of inner and outer loops here is reversed from that of the algorithm in the paper. What we have here is similar to FlashAttention-2 and was originally implemented in the Triton kernel. This lends itself to easy parallelization of the outer loop over the s. –
def flash_attn(Q, K, V, B):
# N is sequence length, d is embedding dimension, B is block-size.
N, d = Q.shape
n_B = N / B
O = zeros(N, d) # Initialize output O as an N x d matrix.
for i in range(n_B): # NOTE: This loop can be parallelized.
Bi = indices(i * B, (i + 1) * B)
Q_Bi = load(Q, Bi) # Load a B x d block of Q.
O_Bi = flash_attn_inner(Q_Bi, K, V, B, d, n_B)
store(O_Bi, O) # Store the results for the corresponding B x d block of output O.
return O
def flash_attn_inner(Q_Bi, K, V, B, d, n_B):
O_Bi, running_sum = zeros(B, d), zeros(B)
for j in range(n_B): # Given a fixed block of Q, loop over all blocks of K and V.
Bj = indices(j * B, (j + 1) * B)
K_Bj, V_Bj = load(K, Bj), load(V, Bj)
S_ij = Q_Bi @ transpose(K_Bj) # Scores are calculated only for a small subset of the N x N matrix.
O_Bi, running_sum = online_softmax(O_Bi, S_ij, V_Bj, running_sum)
return O_Bi
# NOTE: This is without overflow correction.
def online_softmax(O_Bi, S_ij, V_Bj, running_sum):
new_running_sum = running_sum + S_ij.exp().sum(dim=1)
O_Bi = O_Bi * running_sum + S_ij.exp() @ V_Bj
O_Bi = O_Bi / new_running_sum
return O_Bi, new_running_sum
AttentiveSorry, gotta get the bad jokes out while I still can. This first blog post has been six years in waiting, there might not be another one. readers would have noted that the output row depends on only through . So we can calculate just by looking at the corresponding chunk of and thus the outer loop over the s can be parallelized.
Figure is a visual illustration of what the flash_attn_inner function is doing. Following the notation in the paper, and are used to represent the online statistics for the softmax calculation. is similar to running_sum, while keeps track of the max values for overflow correction (which we have omitted in our pseudocode).
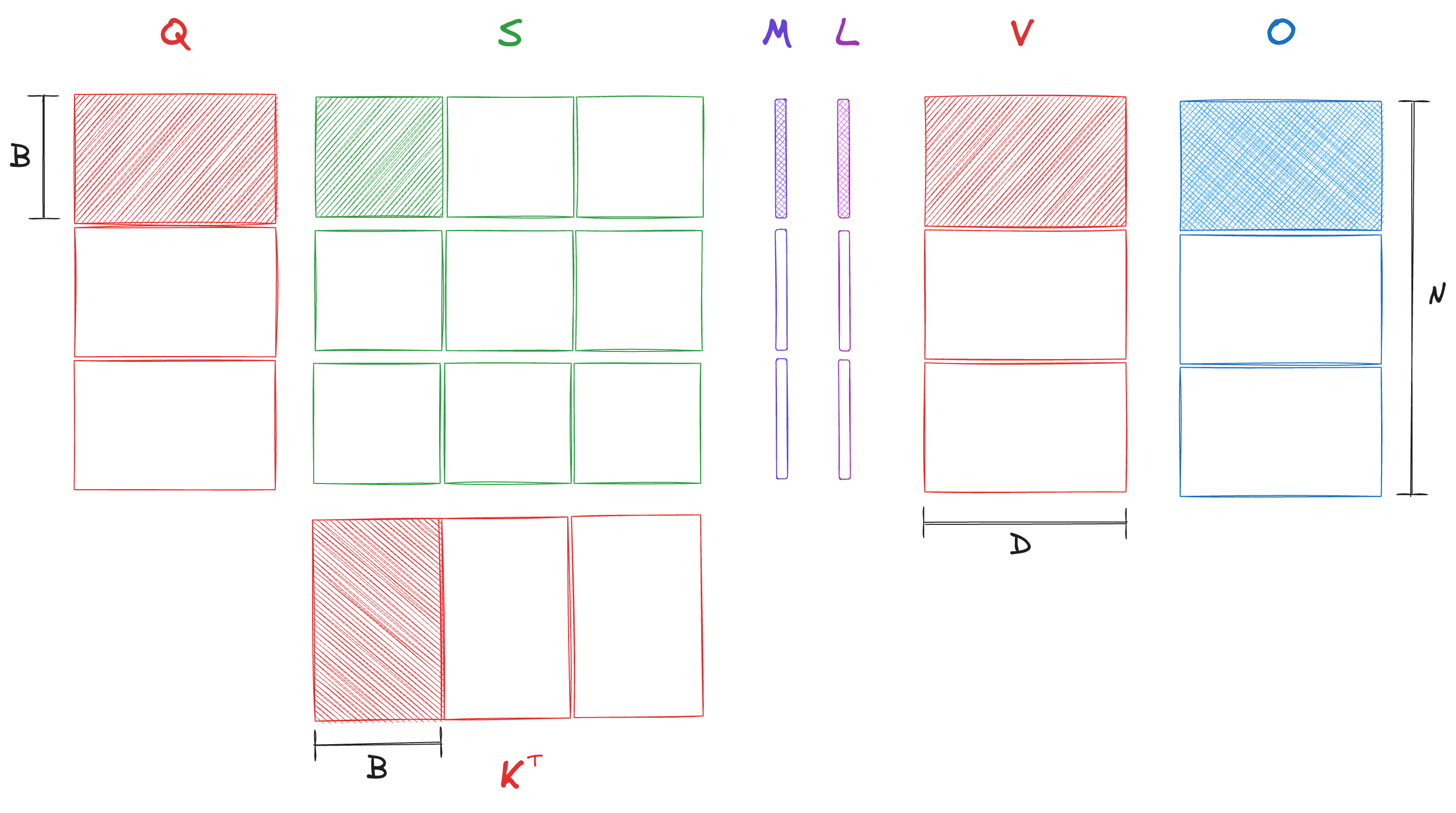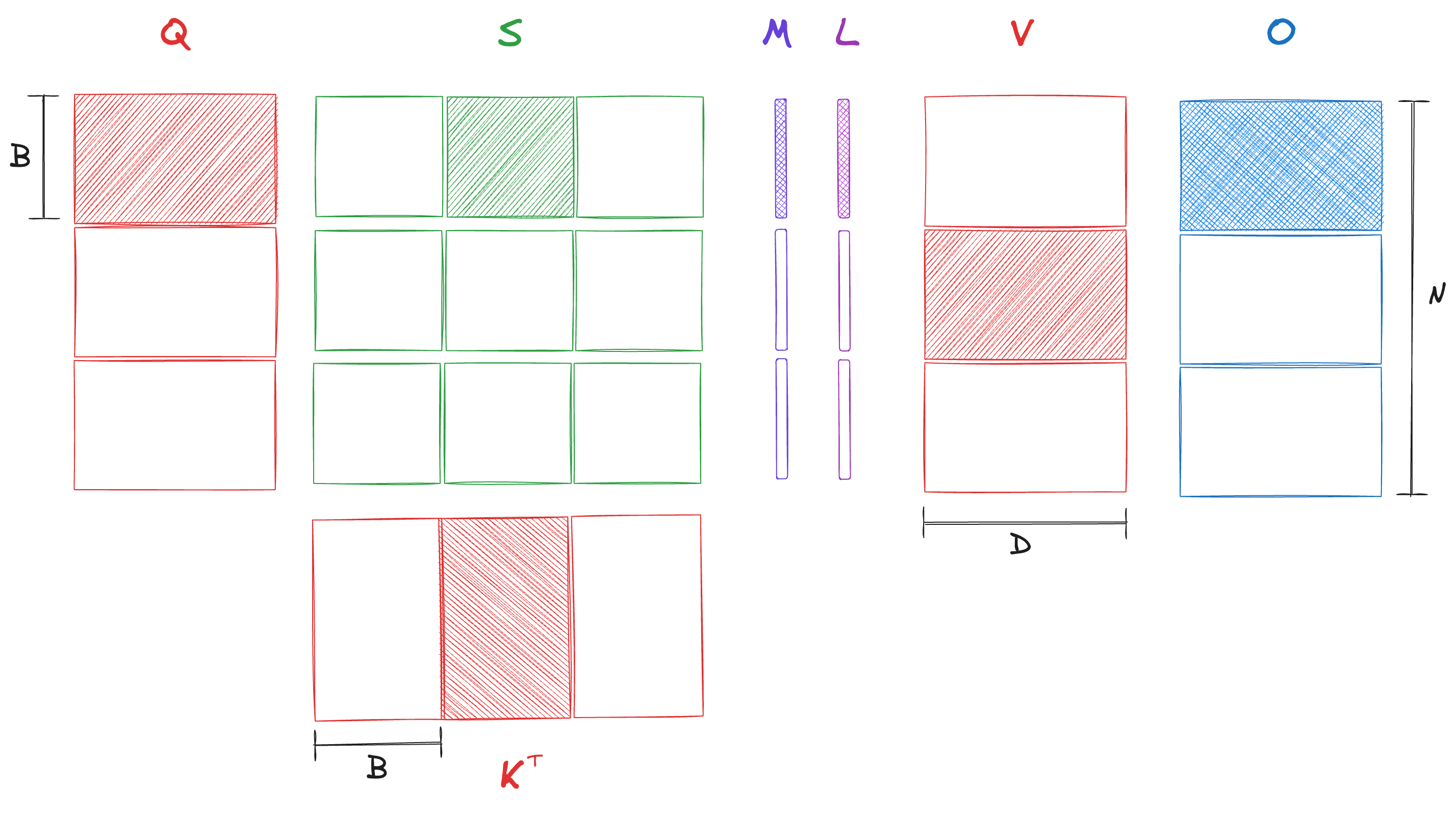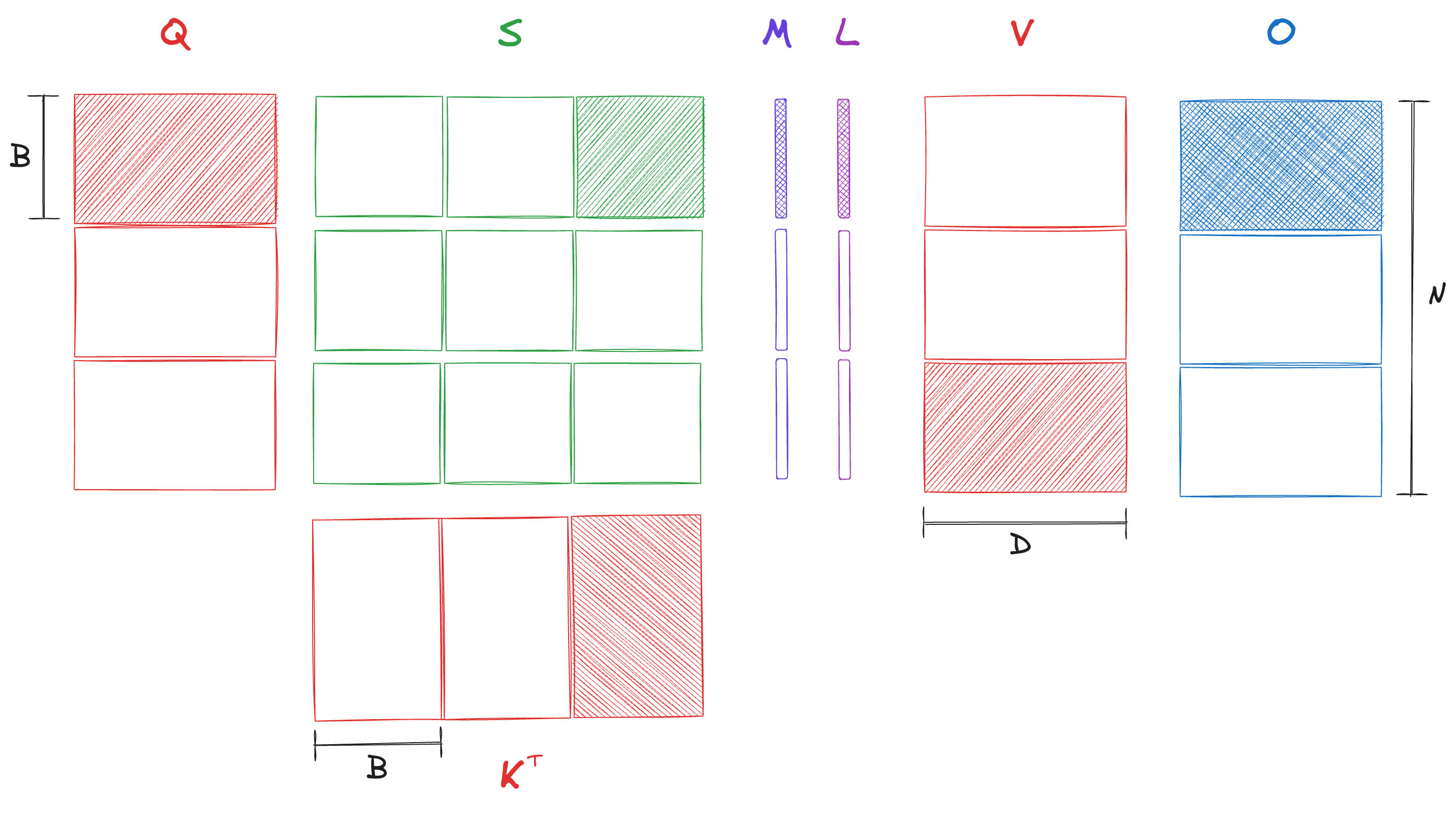
Let’s count the number of times we access the HBM to convince ourselves that these shenanigans are, in fact, helpful –
-
Good ol’ Attention – Loading in , , takes reads, reading/writing and takes accesses, and writing out is another accesses. In total, that’s HBM accesses.
-
FlashAttention – The total number of HBM accesses is times the number of HBM accesses per call to flash_attn_inner. Each flash_attn_inner call takes reads for loading and . Reading and writing mean additional accesses. That adds up to per call. Assuming SRAM size of , we want to choose a big enough block-size such that and . This gives us a grand total of HBM accesses.
Typically, and making , and thus FlashAttention has fewer HBM accesses than vanilla self-attention, which makes it faster. Also, the memory requirement is reduced to because all we need to save to the HBM are the statistics (running_sum above) required to calculate the online softmax (in addition to our inputs and output, of course), whereas vanilla self-attention would have us store the entire attention matrix.
In summary, FlashAttention is an exact algorithm for efficient computation of self-attention that improves on the standard self-attention implementation in the following ways –
| Standard Attention | Flash-Attention | ||
|---|---|---|---|
| FLOPs | |||
| Memory | |||
| HBM accesses |
A note on things that are important but didn’t get the real estate they deserve –
FlashAttention backward pass has an analysis similar to the forward pass – takes extra memory and HBM accesses. The and matrices aren’t stored for the backward pass so as to not blow up the memory and are instead recomputed from and the softmax statistics. The dropout mask is not stored either and recomputed from the pseudo-random generator state stored from the forward pass.
FlashAttention-2 [paper] further optimizes the original FlashAttention algorithm by –
- reducing non-matmul FLOPs. This is important because GPUs have much lower throughput (~10x) for non-matmul FLOPs than matmul FLOPs.
- parallelizing across the sequence dimension (we actually covered this with the reversed loop order thingy above).
- better work partitioning that reduces the need for synchronization and shared memory read/writes.
Flash-Decoding [official post] is a specialization of the FlashAttention algorithm to auto-regressive inference, where the query sequence length is 1. We were parallelizing the outer loop across blocks s, but, for inference, since we will only have a single row in , we will end up under-utilizing the GPU. FlashDecoding solves this issue by dividing the work along the longer key/value sequence dimensions and followed by a reduce operation to get the final output.
Non-trivial implementation. Here is the deal – none of this works unless implemented carefully. Multiple operations need to be fused together to avoid unnecessary kernel launch overheads and reads/writes to HBM. As clean and intuitive as the algorithm itself is, writing all that CUDA code to actually get the speedups that the authors did must have been a lot of work. We have side stepped all those gory details here. The triton kernels do offer a more approachable way to get your hands dirty with the core FlashAttention algorithm than the CUDA/CUTLASS/C implementation, but you will lose some of the finer grained control required to implement things like the work partitioning optimization in FlashAttention-2.
Fin.
Appendix
Pseudocode of the FlashAttention forward pass with the softmax overflow correction –
def flash_attn(Q, K, V, B):
N, d = Q.shape
n_B = N / B
O = zeros(N, d)
for i in range(n_B): # NOTE: This loop can be parallelized.
Bi = indices(i * B, (i + 1) * B)
Q_Bi = load(Q, Bi)
O_Bi = flash_attn_inner(Q_Bi, K, V, B, d, n_B)
store(O_Bi, O)
return O
def flash_attn_inner(Q_Bi, K, V, B, d, n_B):
O_Bi, running_sum, running_max = zeros(B, d), zeros(B), -inf(B)
for j in range(n_B):
Bj = indices(j * B, (j + 1) * B)
K_Bj, V_Bj = load(K, Bj), load(V, Bj)
S_ij = Q_Bi @ transpose(K_Bj)
O_Bi, running_sum, running_max = online_softmax(O_Bi, S_ij, V_Bj, running_sum, running_max)
return O_Bi
# With overflow correction.
def online_softmax(O_Bi, S_ij, V_Bj, running_sum, running_max):
new_running_max = max(running_max, S_ij.max(dim=1)) # Pointwise max.
new_running_sum = running_sum * (running_max - new_running_max).exp() + (S_ij - new_running_max).exp().sum(dim=1)
O_Bi = O_Bi * running_sum * (running_max - curr_running_max).exp() + (S_ij - curr_running_max).exp() @ V_Bj
O_Bi = O_Bi / new_running_sum
return O_Bi, new_running_sum, new_running_max